Tokenization: Background and BPE Explanation
Tokenization is the process of converting raw text into a sequence of integers. These indices are then used to look up embeddings, this is crucial because Neural Networks cannot operate directly on raw text.
In this post, I’ll:
- Briefly describe different tokenization strategies and their tradeoffs;
- Dive into Byte-Pair Encoding (BPE) - the approach, used to train GPT-2;
- Implement an optimized version of BPE from scratch; View code on GitHub.
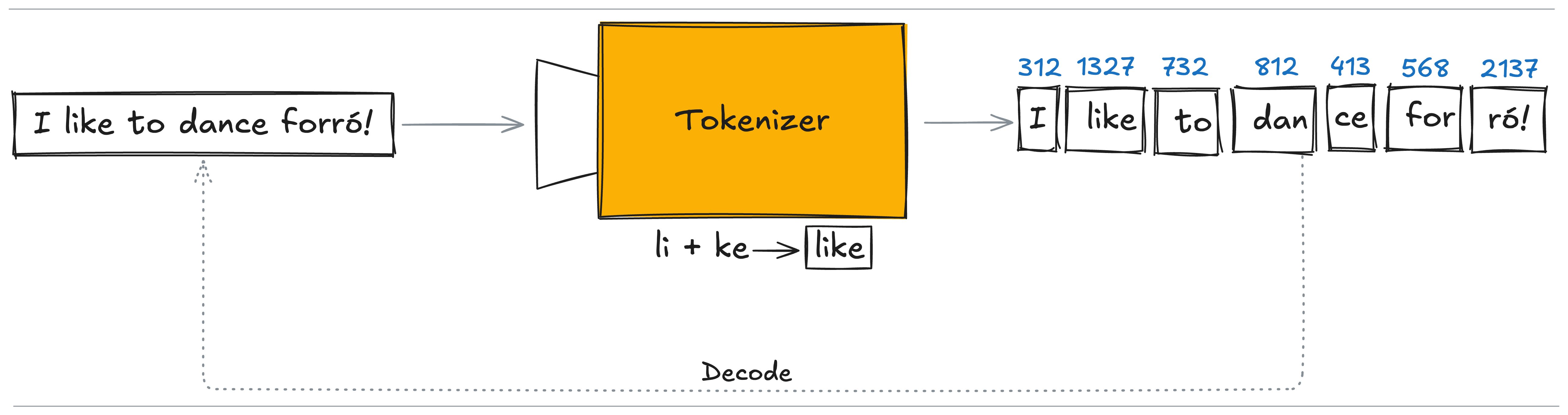
Definitions
To discuss further pros and cons of different approaches, we need the following definitions:
- vocabulary: list of tokens
- vocabulary size: the number of unique tokens in the vocabulary
- encode: function (process of) transforming raw text to the sequence of tokens
- decode: function (process of) transforming the sequence of tokens to the text
We need to ensure that a tokenizer is reversible, meaning:
decode(encode(text)) == text
This guarantees lossless compression of the input into tokens. In practice, many tokenizers aim for “almost reversible” — e.g., normalizing whitespace or punctuation. But for clarity, I assume strict reversibility in this post.
Tokenization Strategies: Character, Byte, and Word
Character-based Tokenizer
In this approach, each character is treated as a token. The mapping from character to integer uses the Unicode code point:
We split our raw text by characters, each character can be converted to Unicode code point using ord function in Python. For example:
assert ord('S') == 83
Pros:
- Simple, language-agnostic
- Fully reversible
Cons:
- Large vocabulary (Unicode 16.0 defines 154,998 code points);
- Most characters are rare, leading to inefficient use of vocabulary;
- Sequence length is large;
Byte-based Tokenizer
This approach uses byte values directly, typically using UTF-8 encoding, where each character is represented between one and four bytes.
Pros:
- Fixed vocabulary size of 256
- Language-agnostic
Cons:
- Sequences become much longer
- High memory usage for Transformer models (due to quadratic cost with sequence length) Note: Several papers attempt to improve byte-level modeling (e.g. MygaByte (2023)), but byte-level models remain niche in practice for now.
Word-based tokenizer
This approach splits the text into words using whitespace and punctuation. Each word is treated as a token.
Pros:
- Interpretable tokens (human-readable)
- Short sequences
Cons:
- Extremely large vocabulary
- Cannot handle unseen words (e.g. typos, new names)
- Poor generalization across morphological variations
Note: Unlike character-based tokenization, the vocab. size is theoretically unbounded — we can always encounter a new word.
(Byte-Pair Encoding) BPE Tokenizer
To combine the strengths of character-level and word-level tokenization, researchers developed subword tokenizers - methods that merge frequent patterns (like words or word parts) while still being able to handle unseen inputs (like typos or new words).
One of the most widely used subword algorithms is Byte-Pair Encoding (BPE), originally a data compression technique adapted for tokenization.
Naive BPE Algorithm:
- Split the corpus into individual bytes.
- Initialize the vocabulary with all 256 possible byte values.
- Repeat until the vocabulary reaches the desired size:
- Count all adjacent token pairs in the corpus (bytes itself in the first iteration).
- Find the most frequent pair.
- Merge that pair into a new token and update the corpus and the vocabulary.
This process allows BPE to gradually build up frequent multi-byte units (like “the”, “tion”, or “love”) while retaining the ability to fall back to individual bytes for rare or unseen patterns.
Details of My Implementation
Code Structure and Flow
The naive version of the BPE algorithm is computationally expensive because it requires iterating over the entire corpus repeatedly to count pair frequencies. To make it more scalable, it’s common to pre-tokenize the corpus to reduce the number of iterations required per training step. Instead of iterating over raw text (which may contain billions of characters), we first split it into individual “words” and count their occurrences.
There are several ways to pre-tokenize text. The original BPE implementation used a simple whitespace split (s.split(" ")), but this doesn’t generalize well. Instead, I use the regex-based pre-tokenization pattern from GPT-2, which better handles punctuation, contractions, and multilingual input:
self.PAT = r"""'(?:[sdmt]|ll|ve|re)| ?\p{L}+| ?\p{N}+| ?[^\s\p{L}\p{N}]+|\s+(?!\S)|\s+"""
This pattern captures: - letters (\p{L}), numbers (\p{N}), and punctuation - space-prefixed tokens and whitespace boundaries
Each “pre-token” is a sequence of Unicode bytes. These become the initial units we merge.
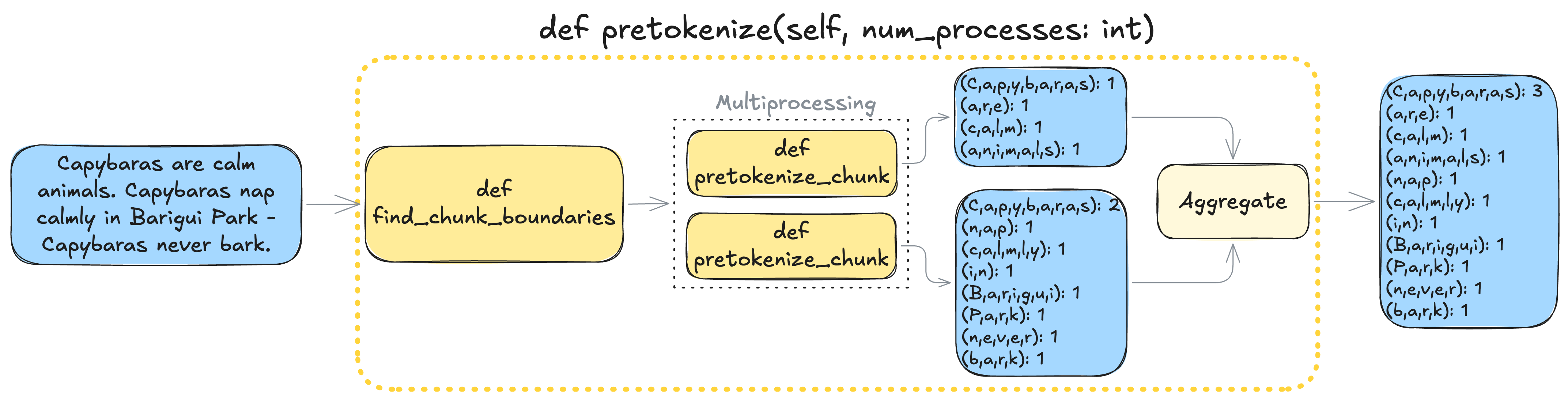
The other functions are described below:
- train: Performs the core BPE training loop, merging token pairs until the target vocabulary size is reached.
def train(self, num_processes: int): - encode: Encodes raw text into a sequence of token IDs using the learned vocabulary and merge rules.
def encode(self, text: str, num_processes: int = 24) -> list[int | bytes]: - encode_iterable: Extension of the previous one, efficiently works with streaming and long texts.
def encode_iterable(self, iterable: Iterator[str], num_processes: int = 1) -> Iterator[int]: - decode: Decodes a sequence of token IDs back into the original string.
def decode(self, ids: list[int]) -> str:
Special Tokens
In practice, we often need to handle special tokens — symbols that aren’t learned through byte merging, but instead have predefined meanings. Common examples include:
- ”<|endoftext|>”: marks the end of a document
- ”<|unk|>”: represents unknown or out-of-vocabulary tokens
These tokens play important roles in both training and inference, so we must detect and preserve them exactly as they appear.
A key challenge is extracting these special tokens efficiently — especially when they overlap or share prefixes. To solve this, I use regular expression-based matching:
st_pat = "(" + "|".join(map(re.escape, self.special_tokens)) + ")"
comp_pat = re.compile(st_pat)
comp_pat.finditer(data) # used in "iter_split_bytes(self, data: str, pattern: re.Pattern | None)"
This approach allows for clean separation of special tokens from the rest of the input before training or encoding. These matches are excluded from merging logic and are assigned fixed token IDs.
Pre-tokenization
The first step in training BPE is to split the corpus into chunks that can be safely processed in parallel. We begin by splitting on the special separator token ”<|endoftext|>”, which typically denotes document boundaries. We use the following function to find split points:
def find_chunk_boundaries(self, file: BinaryIO, desired_num_chunks: int) -> list[int]:
Next, we remove all other special tokens from the text to ensure they don’t interfere with merge statistics. We then apply regex-based pre-tokenization using the self.PAT pattern (defined earlier). This produces a list of “pre-tokens” — typically word-like chunks — and we count the frequency of each one.
From there, we iterate through these pre-tokens to count adjacent byte-pair occurrences (explained more in “Learning Merge Rules”). This avoids traversing the raw corpus repeatedly, but is still can be optimized for large datasets.
Optimization via Parallelism
The key idea is that each chunk can be processed independently. This allows us to pre-tokenize and count pairs in parallel:
with open(self.input_path, "rb") as f:
boundaries = self.find_chunk_boundaries(f, num_processes)
params = []
for start, end in zip(boundaries[:-1], boundaries[1:]):
params.append((start, end))
# run pretokenizer for chunks in parallel
with Pool(num_processes) as p:
counters = p.starmap(self.pretokenize_chunk, params)
and then merge the results:
cnt_pretokens = counters[0]
for cnt_pretokens_step in counters[1:]:
for pretokens in cnt_pretokens_step:
cnt_pretokens[pretokens] = cnt_pretokens.get(pretokens, 0) + cnt_pretokens_step[pretokens]
Implementation Note:
There are two common approaches to representing token sequences during pre-tokenization and merging:
- Index-based (ID) representation: Each pre-token is converted into a seq. of byte IDs (e.g., \(\text{love} \to (108, 111, 118, 101)\)).
This approach is faster during the pre-tokenization step. - Byte-based representation: Each pre-token is treated as a sequence of raw bytes (e.g., \(\text{love} \to (\text{b'l'}, \text{b'o'}, \text{b'v'}, \text{b'e'})\)).
While slower in pre-tokenization, this method is more intuitive.
The snippet below shows the byte-based representation logic:
for pretoken in re.finditer(self.PAT, fragm):
b = pretoken.group().encode("utf-8")
utf8_bytes = tuple(b[i:i+1] for i in range(len(b)))
# utf8_bytes = tuple(b) # for index-based (ID) representation
In practice, index-based representation speeds up the pre-tokenization step by ~2x, but it requires carefully starting the vocabulary at the 256 predefined byte IDs. Meanwhile byte-based representation offers cleaner logic and better performance during the merge step due to necessity of additional access to vocabulary (~2.5x). For offline training with parallelism, the total runtime ends up slightly lower for byte-based implementations.
Learning Merge Rules
The naive implementation of token merging in BPE looks like this:
- Iterate over all adjacent byte pairs in the corpus.
- Count how many times each pair appears.
- Select the most frequent pair, merge it, and repeat. While simple, this approach is inefficient, since it involves scanning every pre-token and all byte pairs at each step.
In practice, most pre-tokens don’t contain the current merge target. This observation allows for a much more efficient algorithm.
Core idea:
Track only the relevant pairs and where they occur. Update only the affected parts of the data. We maintain:
-
pairs_cnt: a counter of how many times each byte-pair occurs. -
pairs_pos: the set pre-token indices and positions inside these pre-tokens where each pair appears.
self.init_pairs()
t = perf_counter()
while self.cur_vsize < self.vocab_size:
best_pair, _ = self.train_step()
At the start of training, we initialize pairs_cnt and pairs_pos once.
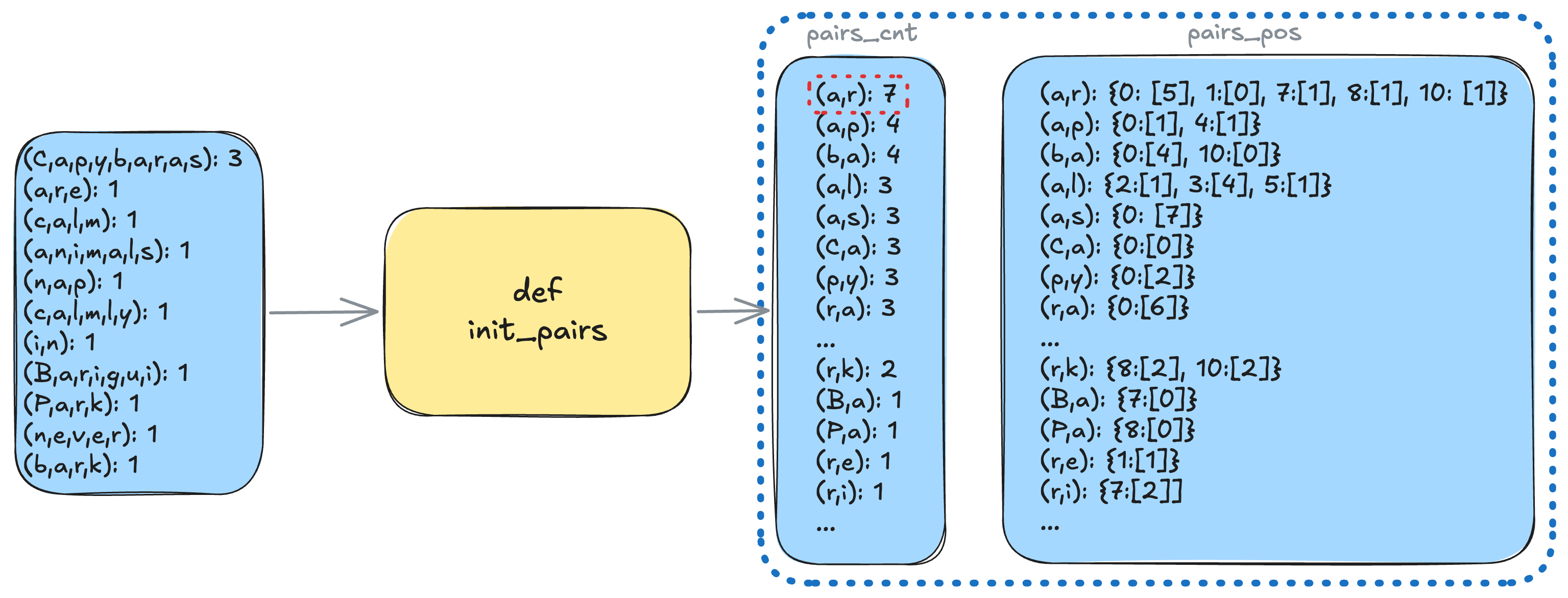
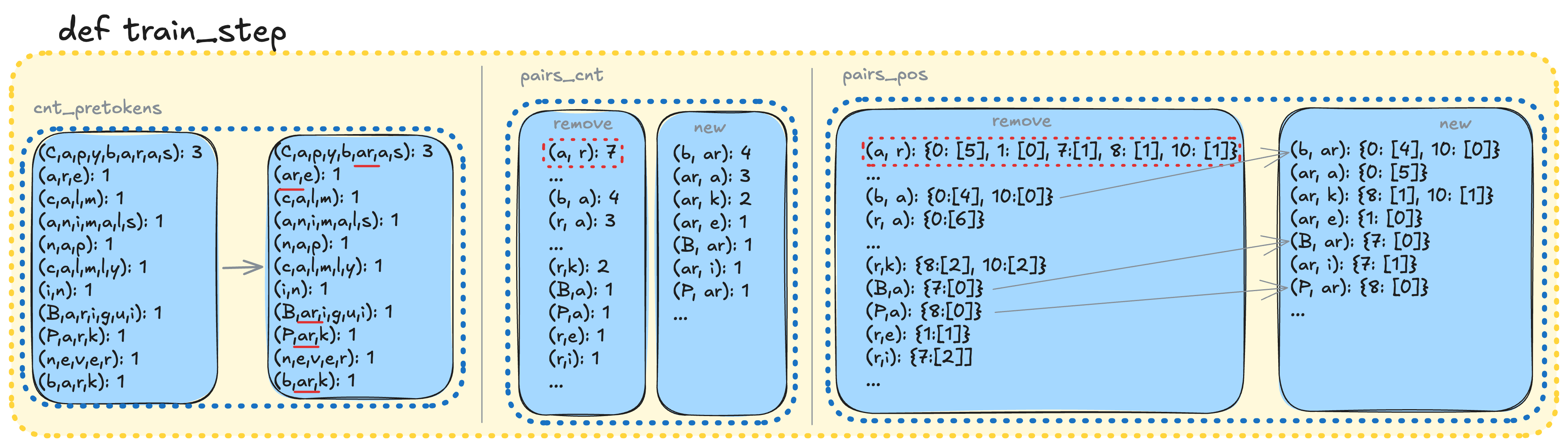
Each training step includes:
- Find the most frequent pair.
- Update merge list.
- Update vocabulary.
- Update only affected pre-tokens.
- update pre-token
- update pairs_cnt and pairs_pos
best_pair, best_pair_cnt = max(self.pairs_cnt.items(), key=lambda x: (x[1], x[0]))
# best_pair, best_pair_cnt = max(self.pairs_cnt.items(), key=lambda x: (x[1], (self.vocab[x[0][0]], self.vocab[x[0][1]]))) # for index-based (ID) representation (~2.5x slower)
# update merges
self.merges.append(best_pair)
# update vocabulary
self.vocab[self.cur_vsize] = best_pair[0] + best_pair[1]
self.tokens2id[best_pair[0] + best_pair[1]] = self.cur_vsize
self.cur_vsize += 1
# modify counter & co-occurence
i_pretokens = list(self.pairs_pos[best_pair].keys())
for pretoken_idx in i_pretokens:
pretokens_old = self.update_pretoken(best_pair, pretoken_idx)
self.update_pairs(pretoken_idx, pretokens_old)
This targeted update strategy avoids unnecessary recomputation and scales much better on large datasets.
Encoding Text
Encoding is the process of converting raw text into a sequence of token IDs. This is similar to the BPE training process and follows these steps:
- Pre-tokenize the text into individual chunks (e.g., words), each represented as a sequence of bytes.
- Iteratively apply merge rules to each pre-token by scanning through the list of BPE merges (in order of creation). Merging stops when no more pairs can be combined.
# create initial list of bytes
b = pretoken.encode("utf-8")
tokens = [b[i:i+1] for i in range(len(b))]
for token1, token2 in self.merges:
# create indices of occurences
indices = []
i = 0
while i < len(tokens) - 1:
if tokens[i] == token1 and tokens[i + 1] == token2:
tokens[i:i+2] = [token1 + token2]
i += 1
return [self.tokens2id[b] for b in tokens]
Notes:
- Each pre-token is processed independently, which means encoding can be parallelized.
- For very large inputs, naive encoding can use excessive memory. To address this, I implemented an
encode_iterable()variant that stream-encodes input in chunks to reduce memory usage.
Decoding Tokens
Decoding is the reverse of encoding: we map token IDs back to their original text. To do this, we first convert the token ID sequence into a stream of bytes, then decode those bytes using UTF-8:
byte_seq = b"".join([self.vocab[i] for i in ids])
text = byte_seq.decode("utf-8", errors="replace")
Note:
Not all byte sequences correspond to valid UTF-8 strings. To handle decoding failures gracefully, we use errors="replace", which substitutes invalid byte sequences with the Unicode replacement character. Alternatively, it can be done by mapping unknown tokens to a special placeholder like <|unk|>.
Conclusion
- Tokenization is a core step in preparing text for Deep Learning.
- BPE combines efficiency and flexibility by merging frequent byte-pairs into meaningful subword units.
- My implementation supports special tokens, parallel pre-tokenization, and a scalable, targeted merging strategy.
- To handle large inputs efficiently, I added a streaming
encode_iterable()function for memory-safe tokenization.
Performance note: Benchmarks were run on an AMD Ryzen Threadripper 7960X (24 cores) using the TinyStories dataset:
- Byte-based pre-tokenization: ~395s (1 core) -> ~18.5s (24 cores)
- Index-based pre-tokenization: ~216s (1 core) -> ~10.6s (24 cores)
- Byte-based training (10K vocab): ~23.8s
- Index-based training (10K vocab): ~59.5s
Enjoy Reading This Article?
Here are some more articles you might like to read next: